What is Catalyst optimizer
An optimizer that automatically finds out the most efficient plan to execute data operations specified in the user’s program.
It “translates” transformations used to build the Dataset to physical plan of execution. Thus, it’s similar to DAG scheduler used to create physical plan of execution of RDD.
It is precious to Dataset in terms of performance. Since it understands the structure of used data and operations made on it, the optimizer can make some decisions helping to reduce time execution
How it works
Let’s first understand the terminology used in understanding the optimizer
- logical plan — series of algebraic or language constructs, as for example: SELECT, GROUP BY or UNION keywords in SQL. It’s usually represented as a tree where nodes are the constructs.
- physical plan — similar to logical because also represented as a tree. But the difference is that physical plan concerns low level operations.
- unoptimized/optimized plans — a plan is considered as unoptimized when optimizer hasn’t worked on it yet. The plan becomes optimized when optimizer passed on it and made some optimizations (e.g.: merging filter() methods, replacing some instructions by another ones, most performant).
So, it helps to move from unoptimized logical query plan to optimized physical plan, achieving that in below steps:
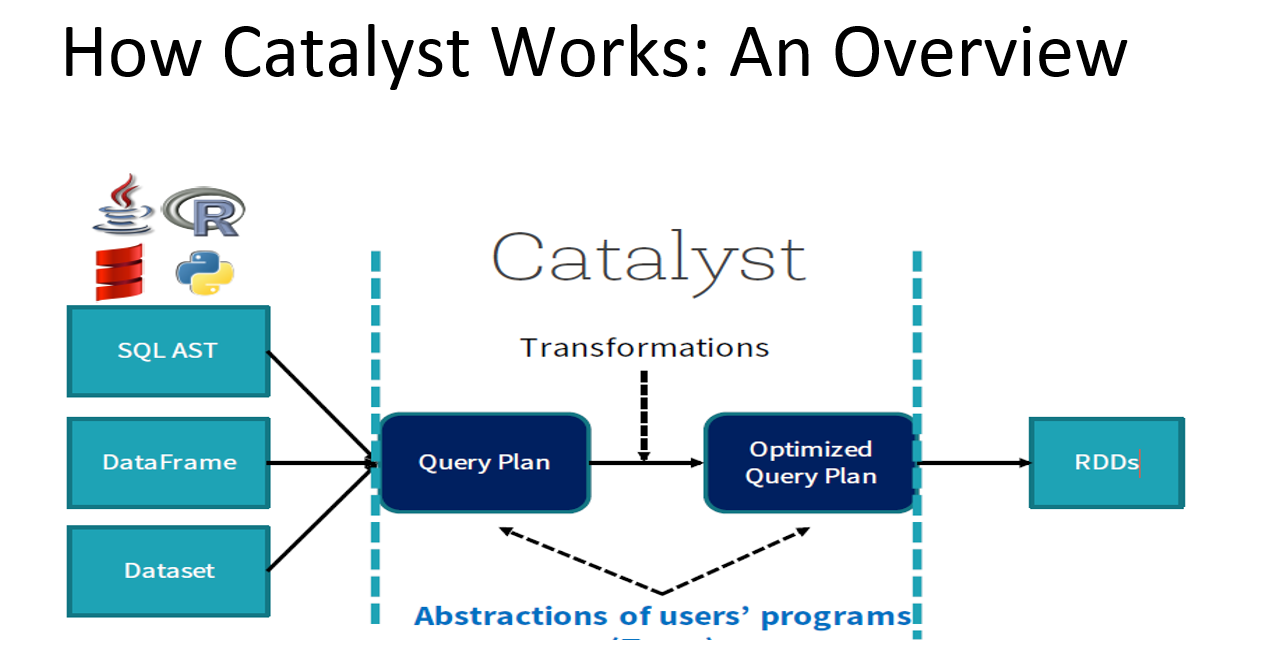
- Optimizer tries to optimize logical query plan through predefined rule-based optimizations. The optimization can consists on:
- predicate or projection pushdown — helps to eliminate data not respecting preconditions earlier in the computation.
- rearrange filter
- conversion of decimals operations to long integer operations
- replacement of some RegEx expressions by Java’s methods startsWith(String) or contains(String)
- if-else clauses simplification
2. Optimized logical plan is created.
3. Optimizer constructs multiple physical plans from optimized logical plan. A physical plan defines how data will be computed. The plans are also optimized. The optimization can concern: merging different filter(), sending predicate/projection pushdown directly to datasource to eliminate some data at data source level.
4. Optimizer determines which physical plan has the lowest cost of execution and choses it as the physical plan used for the computation. CO also has a concept of metrics used to estimate the cost of plans.
5. Optimizer generates bytecode for the best physical plan. The generation is made thanks to Scala’s feature called quasiquotes. This step is optimized by cost-based optimization
6. Once a physical plan is defined, it’s executed and retrieved data is put to Dataset.
Example :
Let’s understand how Catalyst optimizer works for a given query
Trees
A tree is the main data type in the catalyst. A tree contains node object. For each node, there is a node. A node can have one or more children. New nodes are defined as subclasses of TreeNode class. These objects are immutable in nature. The objects can be manipulated using functional transformation.


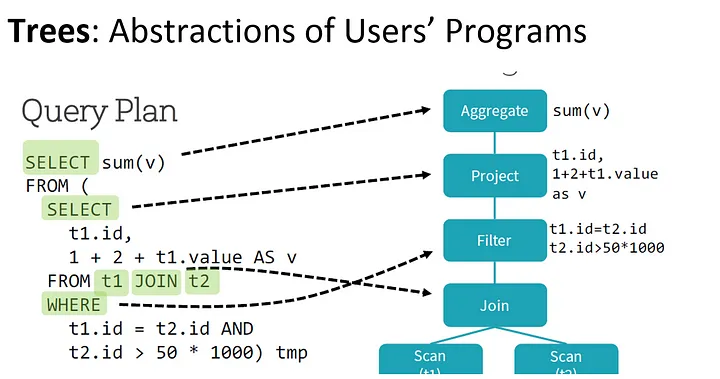
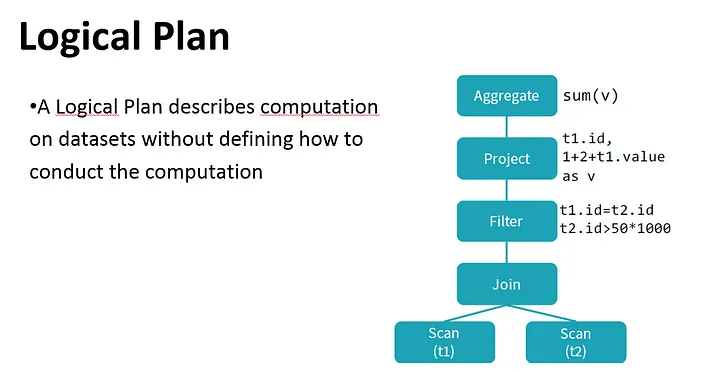
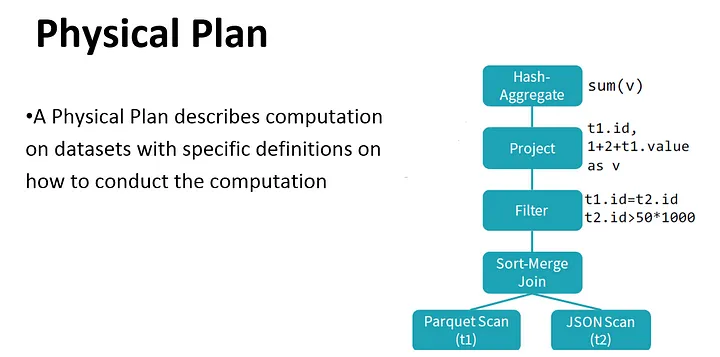
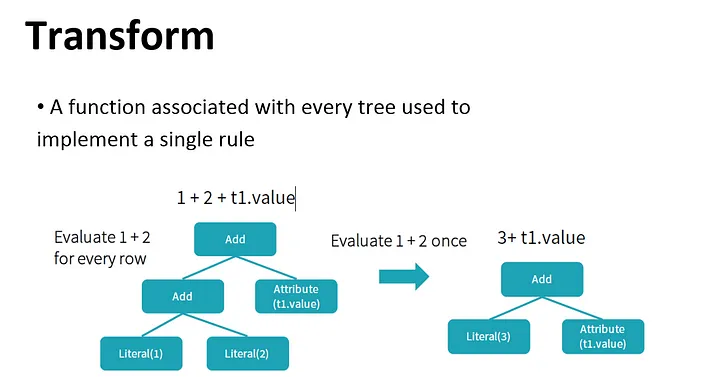

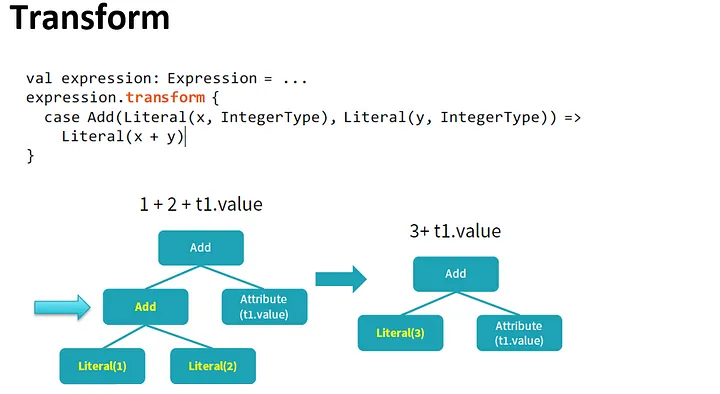
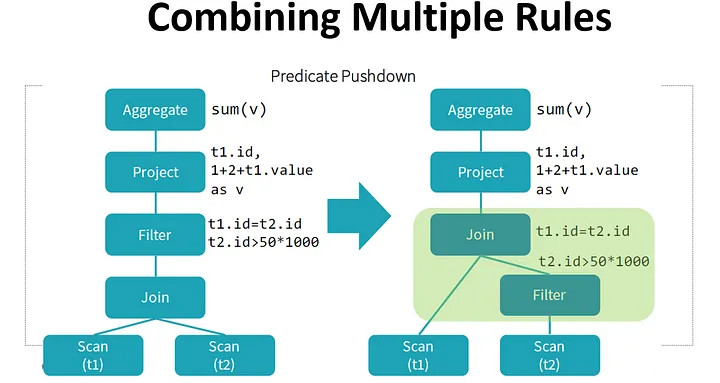
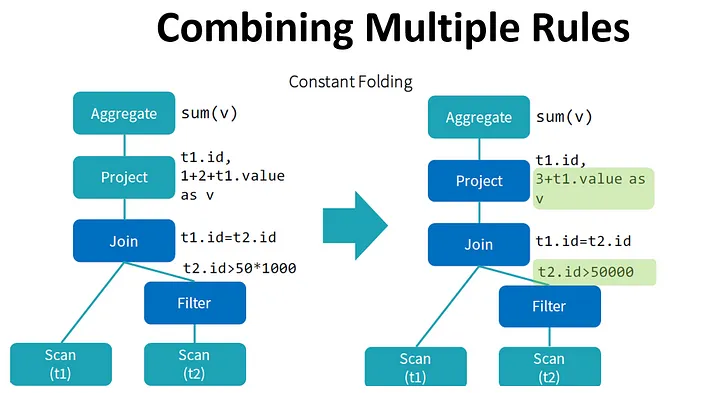
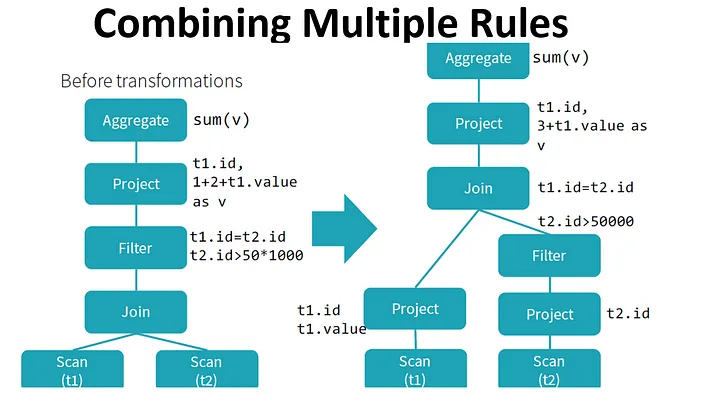
By performing these transformations, the optimizer improves the execution times of relational queries and frees the developer from focusing on the semantics of their application instead of its performance.
Catalyst makes use of Scala’s powerful features such as pattern matching and runtime metaprogramming to allow developers to concisely specify complex relational optimizations.**