Architecture
We talked about spark jobs in chapter 3. In this chapter, we will talk about the architecture and how master, worker, driver and executors are coordinated to finish a job.
Feel free to skip code if you prefer diagrams.
Deployment diagram
We have seen the following diagram in overview chapter.
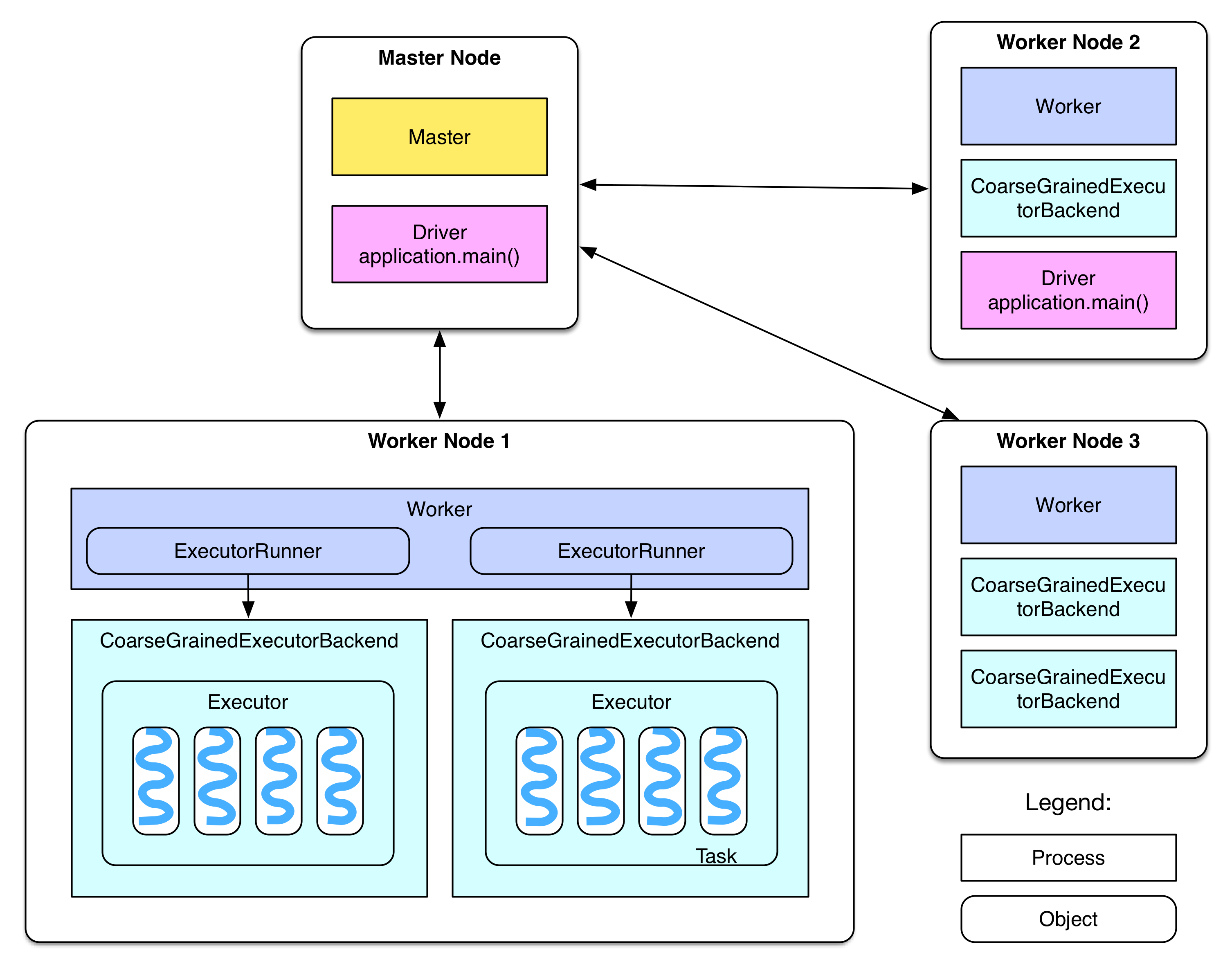
Next, we will talk about some details about it.
Job submission
The diagram below illustrates how driver program (on master node) produces job, and then submits it to worker nodes.
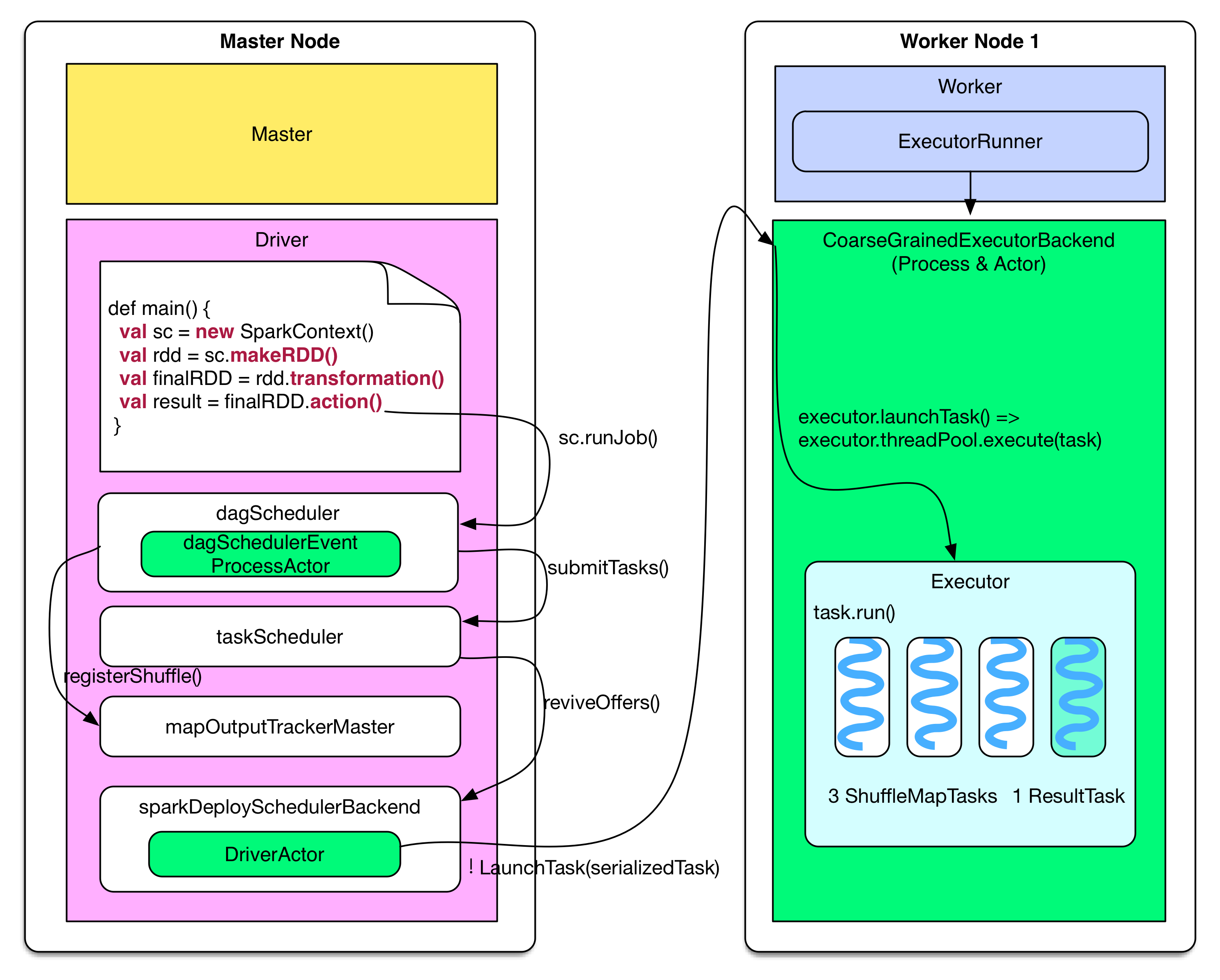
Driver side behavior is equivalent to the code below:
finalRDD.action()
=> sc.runJob()
// generate job, stages and tasks
=> dagScheduler.runJob()
=> dagScheduler.submitJob()
=> dagSchedulerEventProcessActor ! JobSubmitted
=> dagSchedulerEventProcessActor.JobSubmitted()
=> dagScheduler.handleJobSubmitted()
=> finalStage = newStage()
=> mapOutputTracker.registerShuffle(shuffleId, rdd.partitions.size)
=> dagScheduler.submitStage()
=> missingStages = dagScheduler.getMissingParentStages()
=> dagScheduler.subMissingTasks(readyStage)
// add tasks to the taskScheduler
=> taskScheduler.submitTasks(new TaskSet(tasks))
=> fifoSchedulableBuilder.addTaskSetManager(taskSet)
// send tasks
=> sparkDeploySchedulerBackend.reviveOffers()
=> driverActor ! ReviveOffers
=> sparkDeploySchedulerBackend.makeOffers()
=> sparkDeploySchedulerBackend.launchTasks()
=> foreach task
CoarseGrainedExecutorBackend(executorId) ! LaunchTask(serializedTask)
Explanation:
When the following code is evaluated, the program will launch a bunch of driver communications, e.g. job's executors, threads, actors, etc.
val sc = new SparkContext(sparkConf)
This line defines the role of driver
Job logical plan
transformation() in driver program builds a computing chain (a series of RDD). In each RDD:
compute()function defines the computation of records for its partitionsgetDependencies()function defines the dependency relationship across RDD partitions.
Job physical plan
Each action() triggers a job:
- During
dagScheduler.runJob(), different stages are defined - During
submitStage(),ResultTasksandShuffleMapTasksneeded by the stage are produced, then they are packaged inTaskSetand sent toTaskScheduler. IfTaskSetcan be executed, tasks will be submitted tosparkDeploySchedulerBackendwhich will distribute tasks.
Task distribution
After sparkDeploySchedulerBackend gets TaskSet, the Driver Actor sends serialized tasks to CoarseGrainedExecutorBackend Actor on worker node.
Job reception
After receiving tasks, worker will do the following things:
coarseGrainedExecutorBackend ! LaunchTask(serializedTask)
=> executor.launchTask()
=> executor.threadPool.execute(new TaskRunner(taskId, serializedTask))
Executor packages each task into taskRunner, and picks a free thread to run the task. A CoarseGrainedExecutorBackend process has exactly one executor
Task execution
The diagram below shows the execution of a task received by worker node and how driver processes task results.
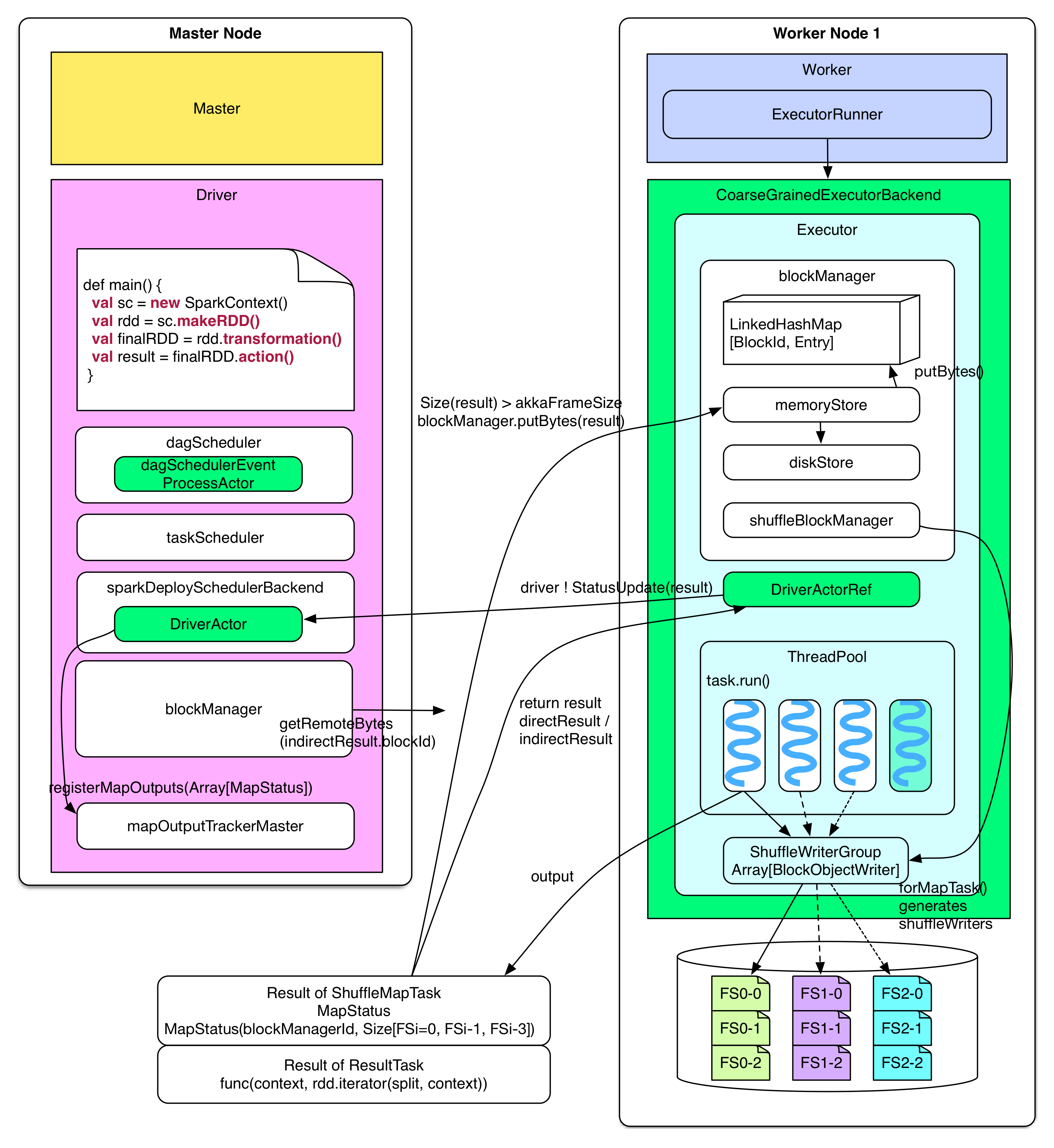
After receiving a serialized task, the executor deserializes it into a normal task, and then runs the task to get directResult which will be sent back to driver. It is noteworthy that data package sent from Actor can not be too big:
- If the result is too big (e.g. the one of
groupByKey), it will be persisted to "memory + hard disk" and managed byblockManager. Driver will only getindirectResultcontaining the storage location. When result is needed, driver will fetch it via HTTP. - If the result is not too big (less than
spark.akka.frameSize = 10MB), then it will be directly sent to driver.
Some more details about blockManager:
When directResult > akka.frameSize, the memoryStore of BlockManager creates a LinkedHashMap to hold the data stored in memory whose size should be less than Runtime.getRuntime.maxMemory * spark.storage.memoryFraction(default 0.6). If LinkedHashMap has no space to save the incoming data, these data will be sent to diskStore which persists data to hard disk if the data storageLevel contains "disk"
In TaskRunner.run()
// deserialize task, run it and then send the result to
=> coarseGrainedExecutorBackend.statusUpdate()
=> task = ser.deserialize(serializedTask)
=> value = task.run(taskId)
=> directResult = new DirectTaskResult(ser.serialize(value))
=> if( directResult.size() > akkaFrameSize() )
indirectResult = blockManager.putBytes(taskId, directResult, MEMORY+DISK+SER)
else
return directResult
=> coarseGrainedExecutorBackend.statusUpdate(result)
=> driver ! StatusUpdate(executorId, taskId, result)
The results produced by ShuffleMapTask and ResultTask are different.
ShuffleMapTaskproducesMapStatuscontaining 2 parts:- the
BlockManagerIdof the task'sBlockManager: (executorId + host, port, nettyPort) - the size of each output
FileSegmentof a task
- the
ResultTaskproduces the execution result of the specifiedfunctionon one partition e.g. Thefunctionofcount()is simply for counting the number of records in a partition. SinceShuffleMapTaskneedsFileSegmentfor writing to disk,OutputStreamwriters are needed. These writers are produced and managed byblockMangerofshuffleBlockManager
In task.run(taskId)
// if the task is ShuffleMapTask
=> shuffleMapTask.runTask(context)
=> shuffleWriterGroup = shuffleBlockManager.forMapTask(shuffleId, partitionId, numOutputSplits)
=> shuffleWriterGroup.writers(bucketId).write(rdd.iterator(split, context))
=> return MapStatus(blockManager.blockManagerId, Array[compressedSize(fileSegment)])
//If the task is ResultTask
=> return func(context, rdd.iterator(split, context))
A series of operations will be executed after driver gets a task's result:
TaskScheduler will be notified that the task is finished, and its result will be processed:
- If it is
indirectResult,BlockManager.getRemotedBytes()will be invoked to fetch actual results.- If it is
ResultTask,ResultHandler()invokes driver side computation on result (e.g.count()takesumoperation on all ResultTask). - If it is
MapStatusofShuffleMapTask, thenMapStatuswill be put intomapStatusesofmapOutputTrackerMaster, which makes it more easy to be queried during reduce shuffle.
- If it is
- If the received task on driver is the last task in the stage, then next stage will be submitted. If the stage is already the last one,
dagSchedulerwill be informed that the job is finished.
After driver receives StatusUpdate(result)
=> taskScheduler.statusUpdate(taskId, state, result.value)
=> taskResultGetter.enqueueSuccessfulTask(taskSet, tid, result)
=> if result is IndirectResult
serializedTaskResult = blockManager.getRemoteBytes(IndirectResult.blockId)
=> scheduler.handleSuccessfulTask(taskSetManager, tid, result)
=> taskSetManager.handleSuccessfulTask(tid, taskResult)
=> dagScheduler.taskEnded(result.value, result.accumUpdates)
=> dagSchedulerEventProcessActor ! CompletionEvent(result, accumUpdates)
=> dagScheduler.handleTaskCompletion(completion)
=> Accumulators.add(event.accumUpdates)
// If the finished task is ResultTask
=> if (job.numFinished == job.numPartitions)
listenerBus.post(SparkListenerJobEnd(job.jobId, JobSucceeded))
=> job.listener.taskSucceeded(outputId, result)
=> jobWaiter.taskSucceeded(index, result)
=> resultHandler(index, result)
// If the finished task is ShuffleMapTask
=> stage.addOutputLoc(smt.partitionId, status)
=> if (all tasks in current stage have finished)
mapOutputTrackerMaster.registerMapOutputs(shuffleId, Array[MapStatus])
mapStatuses.put(shuffleId, Array[MapStatus]() ++ statuses)
=> submitStage(stage)
Shuffle read
In the preceding paragraph, we talked about task execution and result processing, now we will talk about how reducer (tasks needs shuffle) gets the input data. The shuffle read part in last chapter has already talked about how reducer processes input data.
How does reducer know where to fetch data ?
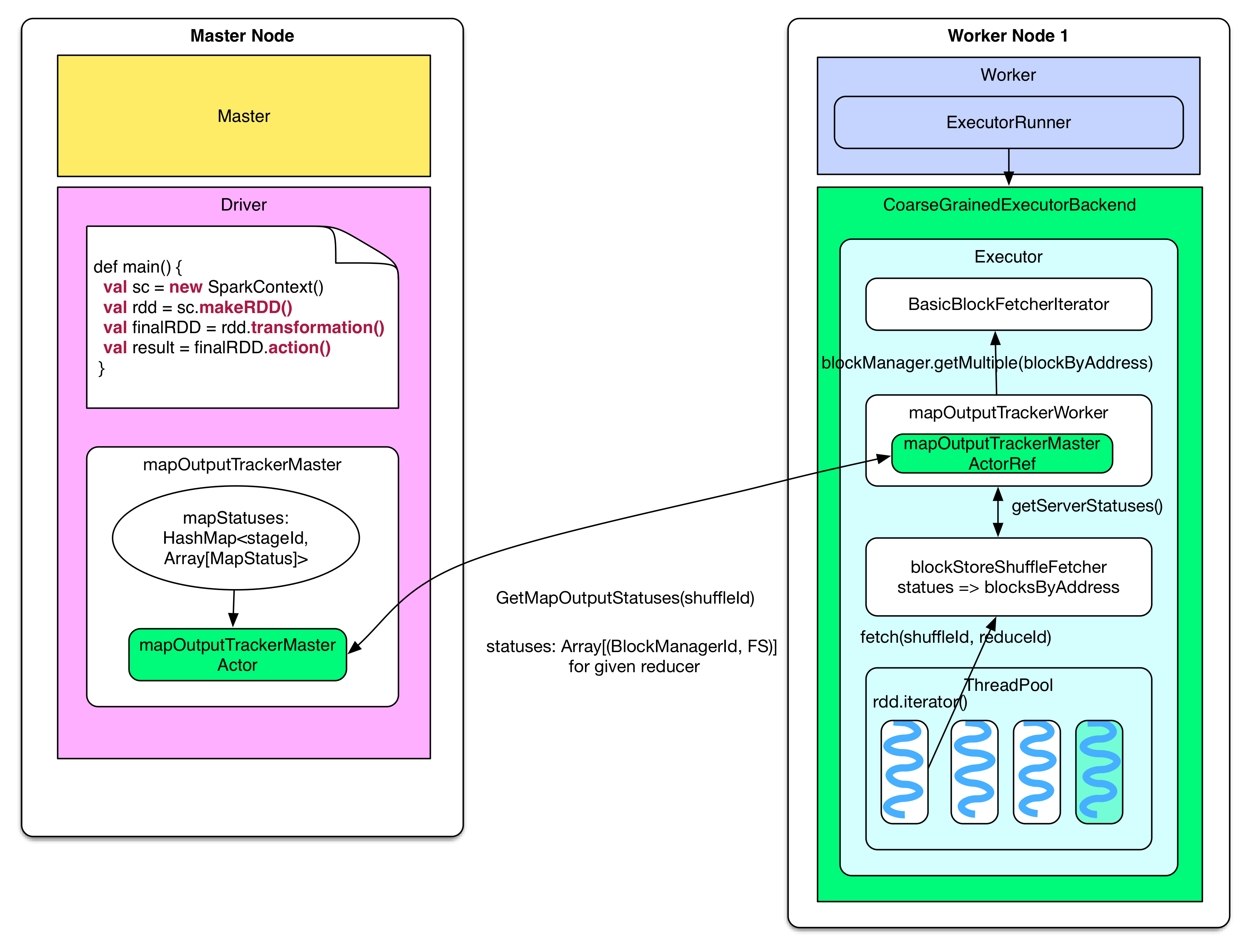
Reducer needs to know on which node the FileSegments produced by ShuffleMapTask of parent stage are. This kind of information is sent to driver’s mapOutputTrackerMaster when ShuffleMapTask is finished. The information is also stored in mapStatuses: HashMap[stageId, Array[MapStatus]]. Given stageId, we can getArray[MapStatus] which contains information about FileSegments produced by ShuffleMapTasks. Array(taskId) contains the location(blockManagerId) and the size of each FileSegment.
When reducer need fetch input data, it will first invoke blockStoreShuffleFetcher to get input data’s location (FileSegments). blockStoreShuffleFetcher calls local MapOutputTrackerWorker to do the work. MapOutputTrackerWorker uses mapOutputTrackerMasterActorRef to communicate with mapOutputTrackerMasterActor in order to get MapStatus. blockStoreShuffleFetcher processes MapStatus and finds out where reducer should fetch FileSegment information, and then it stores this information in blocksByAddress. blockStoreShuffleFetcher tells basicBlockFetcherIterator to fetch FileSegment data.
rdd.iterator()
=> rdd(e.g., ShuffledRDD/CoGroupedRDD).compute()
=> SparkEnv.get.shuffleFetcher.fetch(shuffledId, split.index, context, ser)
=> blockStoreShuffleFetcher.fetch(shuffleId, reduceId, context, serializer)
=> statuses = MapOutputTrackerWorker.getServerStatuses(shuffleId, reduceId)
=> blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = compute(statuses)
=> basicBlockFetcherIterator = blockManager.getMultiple(blocksByAddress, serializer)
=> itr = basicBlockFetcherIterator.flatMap(unpackBlock)
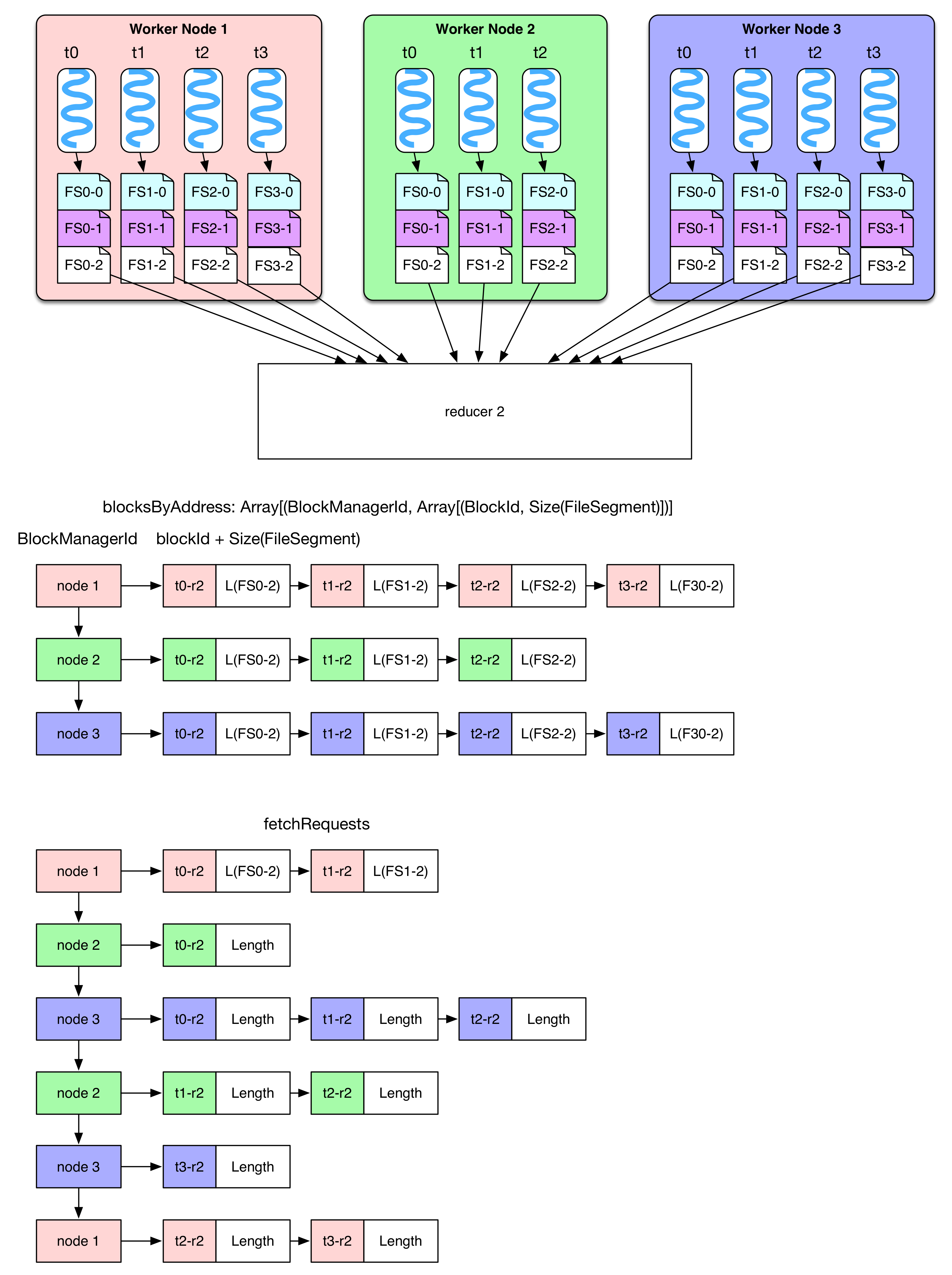
After basicBlockFetcherIterator has received the task of data retrieving, it produces several fetchRequests. Each of them contains the tasks to fetch FileSegments from several nodes. According to the diagram above, we know that reducer-2 needs to fetch FileSegment(FS)(in white) from 3 worker nodes. The global data fetching task can be represented by blockByAddress: 4 blocks from node 1, 3 blocks from node 2, and 4 blocks from node 3
In order to accelerate data fetching process, it makes sense to divide the global tasks into sub tasks(fetchRequest), then every task takes a thread to fetch data. Spark launches 5 parallel threads for each reducer (the same as Hadoop). Since the fetched data will be buffered into memory, one fetch is not able to take too much data (no more than spark.reducer.maxMbInFlight=48MB). Note that 48MB is shared by the 5 fetch threads, so each sub task should take no more than 48MB / 5 = 9.6MB. In the diagram, on node 1, we have size(FS0-2) + size(FS1-2) < 9.6MB, but size(FS0-2) + size(FS1-2) + size(FS2-2) > 9.6MB, so we should break between t1-r2 and t2-r2. As a result, we can see 2 fetchRequests fetching data from node 1. Will there be fetchRequest larger than 9.6MB? The answer is yes. If one FileSegment is too large, it still needs to be fetched in one shot. Besides, if reducer needs some FileSegments already existing on the local, it will do local read. At the end of shuffle read, it will deserialize fetched FileSegment and offer record iterators to RDD.compute()
In basicBlockFetcherIterator:
// generate the fetch requests
=> basicBlockFetcherIterator.initialize()
=> remoteRequests = splitLocalRemoteBlocks()
=> fetchRequests ++= Utils.randomize(remoteRequests)
// fetch remote blocks
=> sendRequest(fetchRequests.dequeue()) until Size(fetchRequests) > maxBytesInFlight
=> blockManager.connectionManager.sendMessageReliably(cmId,
blockMessageArray.toBufferMessage)
=> fetchResults.put(new FetchResult(blockId, sizeMap(blockId)))
=> dataDeserialize(blockId, blockMessage.getData, serializer)
// fetch local blocks
=> getLocalBlocks()
=> fetchResults.put(new FetchResult(id, 0, () => iter))
Some more details:
How does the reducer send fetchRequest to the target node? How does the target node process fetchRequest, read and send back FileSegment to reducer?
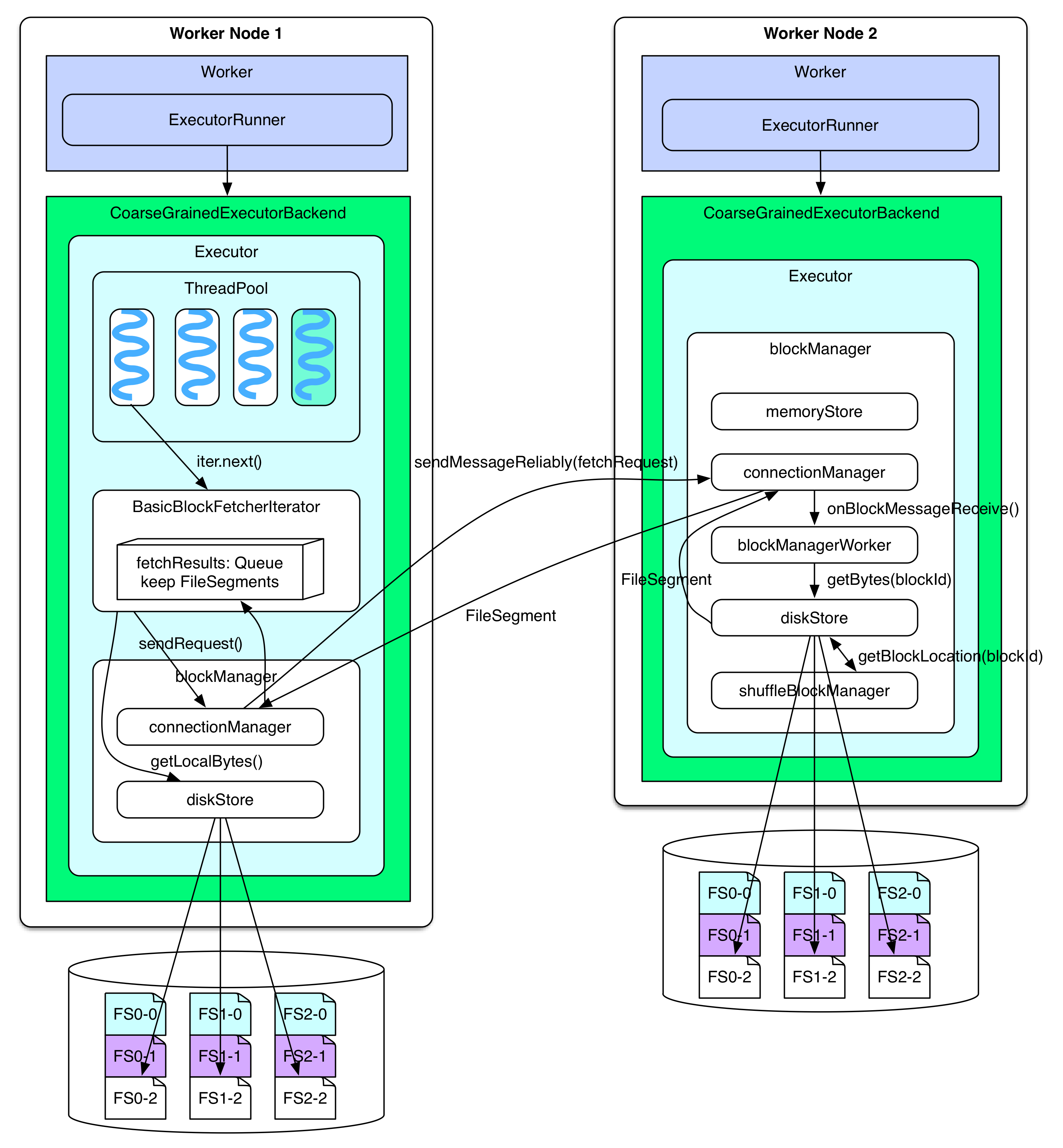
When RDD.iterator() meets ShuffleDependency, BasicBlockFetcherIterator will be called to fetch FileSegments. BasicBlockFetcherIterator uses connectionManager of blockManger to send fetchRequest to connectionManagers on the other nodes. NIO is used for communication between connectionManagers. On the other nodes, for example, after connectionManager on worker node 2 receives a message, it will forward the message to blockManager. The latter uses diskStore to read FileSegments requested by fetchRequest locally, they will still be sent back by connectionManager. If FileConsolidation is activated, diskStore needs the location of blockId given by shuffleBolockManager. If FileSegment is no more than spark.storage.memoryMapThreshold = 8KB, then diskStore will put FileSegment into memory when reading it, otherwise, The memory mapping method in FileChannel of RandomAccessFile will be used to read FileSegment, thus large FileSegment can be loaded into memory.
When BasicBlockFetcherIterator receives serialized FileSegments from the other nodes, it will deserialize and put them in fetchResults.Queue. You may notice that fetchResults.Queue is similar to softBuffer in Shuffle detials chapter. If the FileSegments needed by BasicBlockFetcherIterator are local, they will be found locally by diskStore, and put in fetchResults. Finally, reducer reads the records from FileSegment and processes them.
After the blockManager receives the fetch request
=> connectionManager.receiveMessage(bufferMessage)
=> handleMessage(connectionManagerId, message, connection)
// invoke blockManagerWorker to read the block (FileSegment)
=> blockManagerWorker.onBlockMessageReceive()
=> blockManagerWorker.processBlockMessage(blockMessage)
=> buffer = blockManager.getLocalBytes(blockId)
=> buffer = diskStore.getBytes(blockId)
=> fileSegment = diskManager.getBlockLocation(blockId)
=> shuffleManager.getBlockLocation()
=> if(fileSegment < minMemoryMapBytes)
buffer = ByteBuffer.allocate(fileSegment)
else
channel.map(MapMode.READ_ONLY, segment.offset, segment.length)
Every reducer has a BasicBlockFetcherIterator, and one BasicBlockFetcherIterator could, in theory, hold 48MB of fetchResults. As soon as one FileSegment in fetchResults is read off, some FileSegments will be fetched to fill that 48MB.
BasicBlockFetcherIterator.next()
=> result = results.task()
=> while (!fetchRequests.isEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
sendRequest(fetchRequests.dequeue())
}
=> result.deserialize()
Discussion
In terms of architecture design, functionalities and modules are pretty independent. BlockManager is well designed, but it seems to manage too many things (data block, memory, disk and network communication)
This chapter discussed how the modules of spark system are coordinated to finish a job (production, submission, execution, results collection, results computation and shuffle). A lot of code is pasted, many diagrams are drawn. More details can be found in source code, if you want.
If you also want to know more about blockManager, please refer to Jerry Shao's blog (in Chinese).