Broadcast
As its name implies, broadcast means sending data from one node to all other nodes in the cluster. It's useful in many situations, for example we have a table in the driver, and other nodes need it as a lookup table. With broadcast we can send this table to all nodes and tasks will be able to do local lookups. Actually, it is challenging to implement a broadcast mechanism that is reliable and efficient. Spark's documentation says:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
Why read-only?
This is a consistency problem. If a broadcasted variable can be mutated, once it's modified in some node, should we also update the copies on other nodes? If multiple nodes have updated their copies, how do we determine an order to synchronize these independent updates? There's also fault-tolerance problem coming in. To avoid all these tricky problems with data consistency, Spark only supports read-only broadcast variables.
Why broadcast to nodes but not tasks?
Each task runs inside a thread, and all tasks in a process belong to the same Spark application. So a single read-only copy in each node (executor) can be shared by all tasks.
How to use broadcast?
An example of a driver program:
val data = List(1, 2, 3, 4, 5, 6)
val bdata = sc.broadcast(data)
val rdd = sc.parallelize(1 to 6, 2)
val observedSizes = rdd.map(_ => bdata.value.size)
Driver uses sc.broadcast() to declare the data to broadcast. The type of bdata is Broadcast. rdd.transformation(func) uses bdata directly inside its function like a local variable.
How is broadcast implemented?
The implementation behind the broadcast feature is quite interesting.
Distribute metadata of the broadcast variable
Driver creates a local directory to store the data to be broadcasted and launches a HttpServer with access to the directory. The data is actually written into the directory when the broadcast is called (val bdata = sc.broadcast(data)). At the same time, the data is also written into driver's blockManger with a StorageLevel memory + disk. Block manager allocates a blockId (of type BroadcastBlockId) for the data. When a transformation function uses the broadcasted variable, the driver's submitTask() will serialize its metadata and send it along with the serialized function to all nodes. Akka system impose message size limits so we can not use it to broadcast the actual data.
Why driver put the data in both local disk directory and block manager? The copy on the local disk directory is for the HttpServer, and the copy in block manager is to facilitate the usage of this data inside the driver program.
Then when the real data is broadcasted? When an executor deserializes the task it has received, it also gets the broadcast variable's metadata, in the form of a Broadcast object. It then calls the readObject() method of the metadata object (bdata variable). This method will first check the local block manager to see if there's already a local copy. If not, the data will be fetched from the driver. Once the data is fetched, it's stored in the local block manager for subsequent uses.
Spark has actually 2 different implementations of the data fetching.
HttpBroadcast
This method fetches data through an http connection between the executor and the driver.
Driver creates a HttpBroadcast object and it's this object's job to store the broadcast data into the driver's block manager. In the same time, as we described earlier, the data is written on the local disk, for example in a directory named /var/folders/87/grpn1_fn4xq5wdqmxk31v0l00000gp/T/spark-6233b09c-3c72-4a4d-832b-6c0791d0eb9c/broadcast_0.
Driver and executor instantiate a
broadcastMangerobject during initialization. The local directory is created byHttpBroadcast.initialize()method. This method also launches the http server.
The actual fetching is just data transmission between two nodes with an http connection.
The problem of HttpBroadcast is network bandwidth bottleneck in the driver node since it sends data to all other worker nodes at the same time.
TorrentBroadcast
To solve the driver network bottleneck problem in HttpBroadcast, Spark introduced a new broadcast implementation called TorrentBroadcast which is inspired by BitTorrent. The basic concept of this method is to cut the broadcast data in blocks, and executors who have already fetched data blocks can themselves be the data source.
Unlike the data transfer in HttpBroadcast, TorrentBroadcast uses blockManager.getRemote() => NIO ConnectionManager to do the job. The actual sending and receiving process is quite similar with the cached rdd that we've talked about in the last chapter (check last diagram in CacheAndCheckpoint.
Let's see some details in TorrentBroadcast:
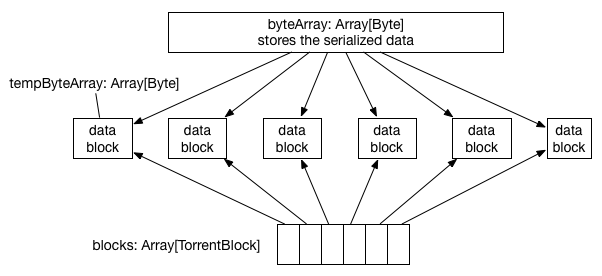
Driver
The driver serializes the data into ByteArray and then cut it into BLOCK_SIZE (defined by spark.broadcast.blockSize = 4MB) blocks. After the cut the original ByteArray will be collected but there's a temporary moment we have 2 copies of the data in memory.
After the cut, information about the blocks (called metadata) is stored in driver's block manager with a storage level at memory + disk. At this time, driver's blockManagerMaster will also be informed that the metadata is successfully stored. This is an important step because blockManagerMaster can be accessed by all executors, meaning that block metadata has now become global data of the cluster.
Driver then finishes its work by physically storing the data blocks under its block manager.
Executor
Upon receiving a serialized task, an executor deserializes it first. The deserialization also includes the broadcast metadata, whose type is TorrentBroadcast. Then its TorrentBroadcast.readObject() method is called. Similar to the general steps illustrated above, the local block manager will be checked first to see if some data blocks have already been fetched. If not, executor will ask driver's blockManagerMaster for the data block's metadata. Then the BitTorrent process starts to fetch the data blocks.
BitTorrent process: an arrayOfBlocks = new Array[TorrentBlock](totalBlocks) is allocated locally to store the fetched data. TorrentBlock is a wrapper over a data block. The actual fetching order is randomized. For example if there's 5 blocks to fetch in total, the fetching order may be 3-1-2-4-5. Then the executor starts to fetch the data block one by one: local blockManager => local connectionManager => driver/other executor's blockManager => data. Each fetched block is stored under local block manager and driver's blockManagerMaster is informed that this block has been successfully fetched. As you'll guess, this is an important step because now all other nodes in the cluster know that there's a new data source for this block. If another node starts to fetch the same block, it'll randomly choose one data source. With more and more blocks being fetched, we'll have more data sources and the whole broadcast will be accelerated. There's a good illustration about BitTorrent on wikipedia.
When all the data blocks are fetched locally, a big Array[Byte] will be allocated to reconstitute the original broadcast data from blocks. Finally this array gets deserialized and is stored under local block manager. Notice that once we have the broadcast variable in local block manager, we can safely delete the fetched data blocks (which are also stored in local block manager).
One more question: what about broadcasting an RDD? In fact nothing bad will happen. This RDD will be evaluated in each executor so that each node has a copy of its result.
Discussion
Broadcasting shared variables is a very handy feature. In Hadoop we have the DistributedCache and it's used in many situations. For example, parameters of -libjars are sent to all nodes by using DistributedCache. However in Hadoop broadcasted data needs to be uploaded to HDFS first and it has no mechanism to share data between tasks in the same node. Say if some node needs to process 4 mappers coming from the same job, then the broadcast variable will be stored 4 times in this node (one copy in each mapper's working directory). An advantage of this approach is that by using HDFS we won't have the bottleneck problem since HDFS does the job of cutting data into blocks and distributing them across the cluster.
For Spark, broadcast cares about sending data to all nodes as well as letting tasks of the same node share data. Spark's block manager solves the problem of sharing data between tasks in the same node. Storing shared data in local block manager with a storage level at memory + disk guarantees that all local tasks can access the shared data, in this way we avoid storing multiple copies. Spark has 2 broadcast implementations. The traditional HttpBroadcast has the bottleneck problem around the driver node. TorrentBroadcast solves this problem but it starts slower since it only accelerate the broadcast after some amount of blocks fetched by executors. Also in Spark, the reconstitution of original data from data blocks needs some extra memory space.
In fact Spark also tried an alternative called TreeBroadcast. Interested reader can check the technical report: Performance and Scalability of Broadcast in Spark.
In my opinion the broadcast feature can even be implemented by using multicast protocols. But multicast is UDP based, we'll need mechanisms on reliability in the application layer.