Cache And Checkpoint
cache (or persist) is an important feature which does not exist in Hadoop. It makes Spark much faster to reuse a data set, e.g. iterative algorithm in machine learning, interactive data exploration, etc. Different from Hadoop MapReduce jobs, Spark's logical/physical plan can be very large, so the computing chain could be too long that it takes lots of time to compute RDD. If, unfortunately, some errors or exceptions occur during the execution of a task, the whole computing chain needs to be re-executed, which is considerably expensive. Therefore, we need to checkpoint some time-consuming RDDs. Thus, even if the following RDD goes wrong, it can continue with the data retrieved from checkpointed RDDs.
cache()
Let's take the GroupByTest in chapter Overview as an example, the FlatMappedRDD has been cached, so job 1 can just start with FlatMappedRDD, since cache() makes the repeated data get shared by jobs of the same application.
Logical plan:
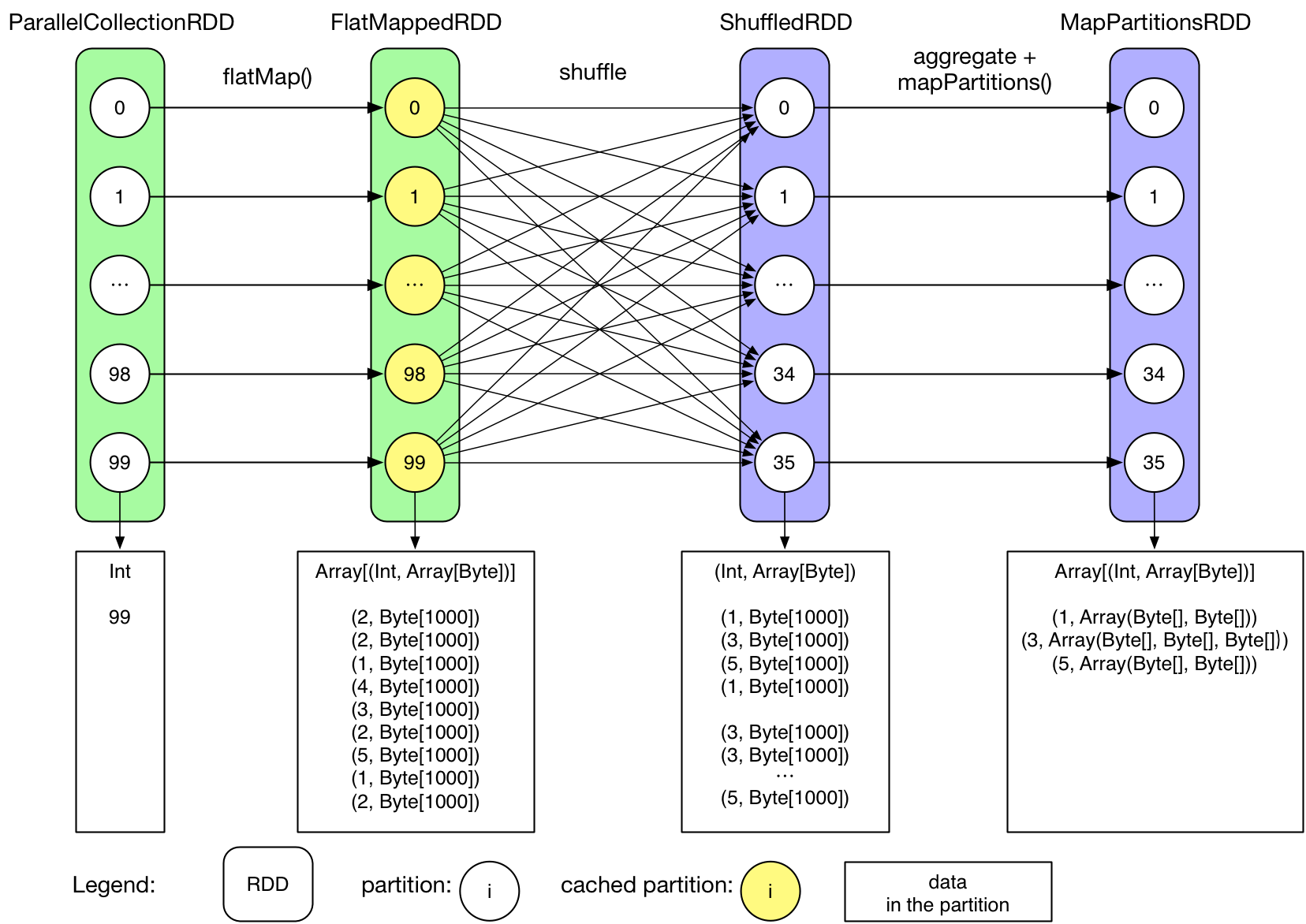 Physical plan:
Physical plan:
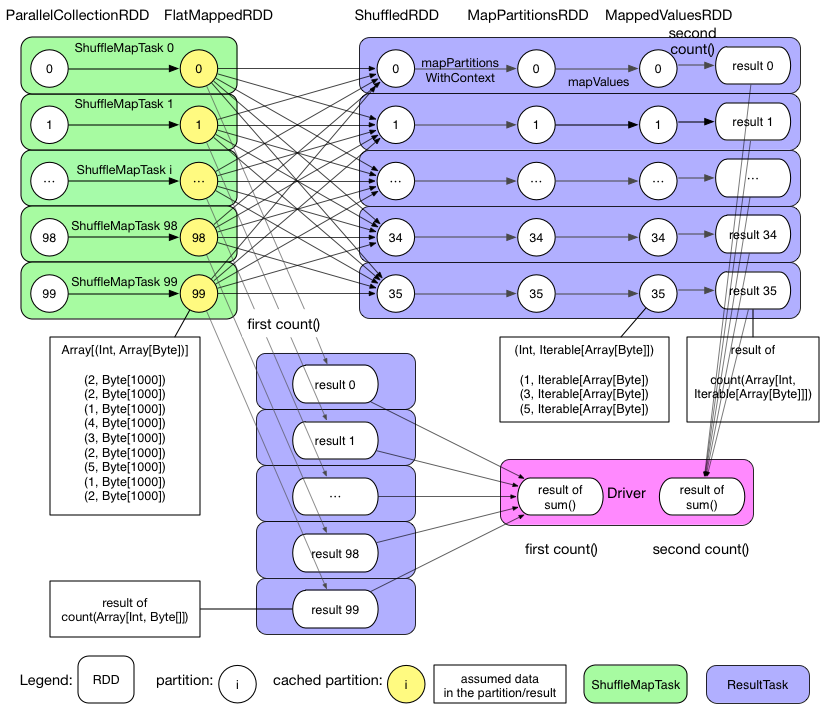
Q: What kind of RDD needs to be cached ?
Those which will be repeatedly computed and are not too large.
Q: How to cache an RDD ?
Just do a rdd.cache() in driver program, where rdd is the RDD accessible to users, e.g. RDD produced by transformation(), but some RDD produced by Spark (not user) during the execution of a transformation can not be cached by user, e.g. ShuffledRDD, MapPartitionsRDD during reduceByKey(), etc.
Q: How does Spark cache RDD ?
We can just make a guess. Intuitively, when a task gets the first record of an RDD, it will test if this RDD should be cached. If so, the first record and all the following records will be sent to blockManager's memoryStore. If memoryStore can not hold all the records, diskStore will be used instead.
The implementation is similar to what we can guess, but the difference is that Spark will test whether the RDD should be cached or not just before computing the first partition. If the RDD should be cached, the partition will be computed and cached into memory. cache only uses memory. Writing to disk is called checkpoint.
After calling rdd.cache(), rdd becomes persistRDD whose storageLevel is MEMORY_ONLY. persistRDD will tell driver that it needs to be persisted.
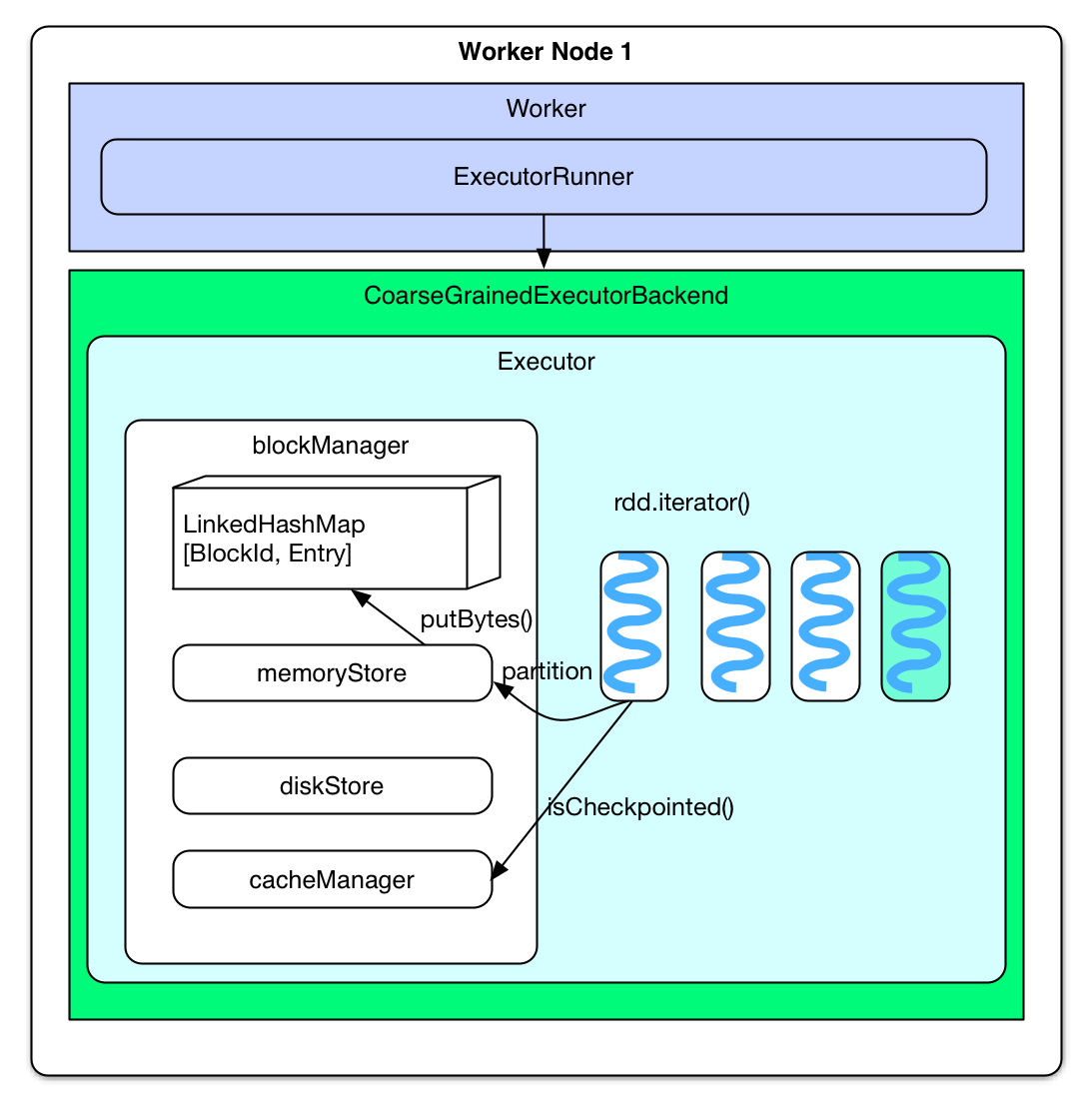
The above can be found in the following source code
rdd.iterator()
=> SparkEnv.get.cacheManager.getOrCompute(thisRDD, split, context, storageLevel)
=> key = RDDBlockId(rdd.id, split.index)
=> blockManager.get(key)
=> computedValues = rdd.computeOrReadCheckpoint(split, context)
if (isCheckpointed) firstParent[T].iterator(split, context)
else compute(split, context)
=> elements = new ArrayBuffer[Any]
=> elements ++= computedValues
=> updatedBlocks = blockManager.put(key, elements, tellMaster = true)
When rdd.iterator() is called to compute some partitions in the rdd, a blockId will be used to indicate which partition to cache, where blockId is of RDDBlockId type which is different from other data types in memoryStore like result of task. And then, partitions in blockManger will be checked to see whether they are checkpointed. If so, it will say that the task has already been executed, no more computation is needed for this partition. The elements of type ArrayBuffer will take all records of the partition from the check point. If not, the partition will be computed first, then all its records will be put into elements. Finally, elements will be submitted to blockManager for caching.
blockManager saves elements (partition) into LinkedHashMap[BlockId, Entry] inside memoryStore. If partition is bigger than memoryStore's capacity (60% heap size), then just return by saying not being able to hold the data. If the size is ok, it will then drop some RDD partitions which was cached earlier in order to create space for the new incoming partitions. If the created space is enough, the new partition will be put into LinkedHashMap; if not, return by saying not enough space again. It is worth mentioning that the old partitions which belong to the RDD of the new partitions will not be dropped. Ideally, "first cached, first dropped".
Q: How to read cached RDD ?
When a cached RDD is being recomputed (in next job), task will read blockManager directly from memoryStore. Specifically, during the computation of some RDD partitions (by calling rdd.iterator()), blockManager will be asked whether they are cached or not. If the partition is cached in local, blockManager.getLocal() will be called to read data from memoryStore. If the partition was cached on the other nodes, blockManager.getRemote() will be called. See below:
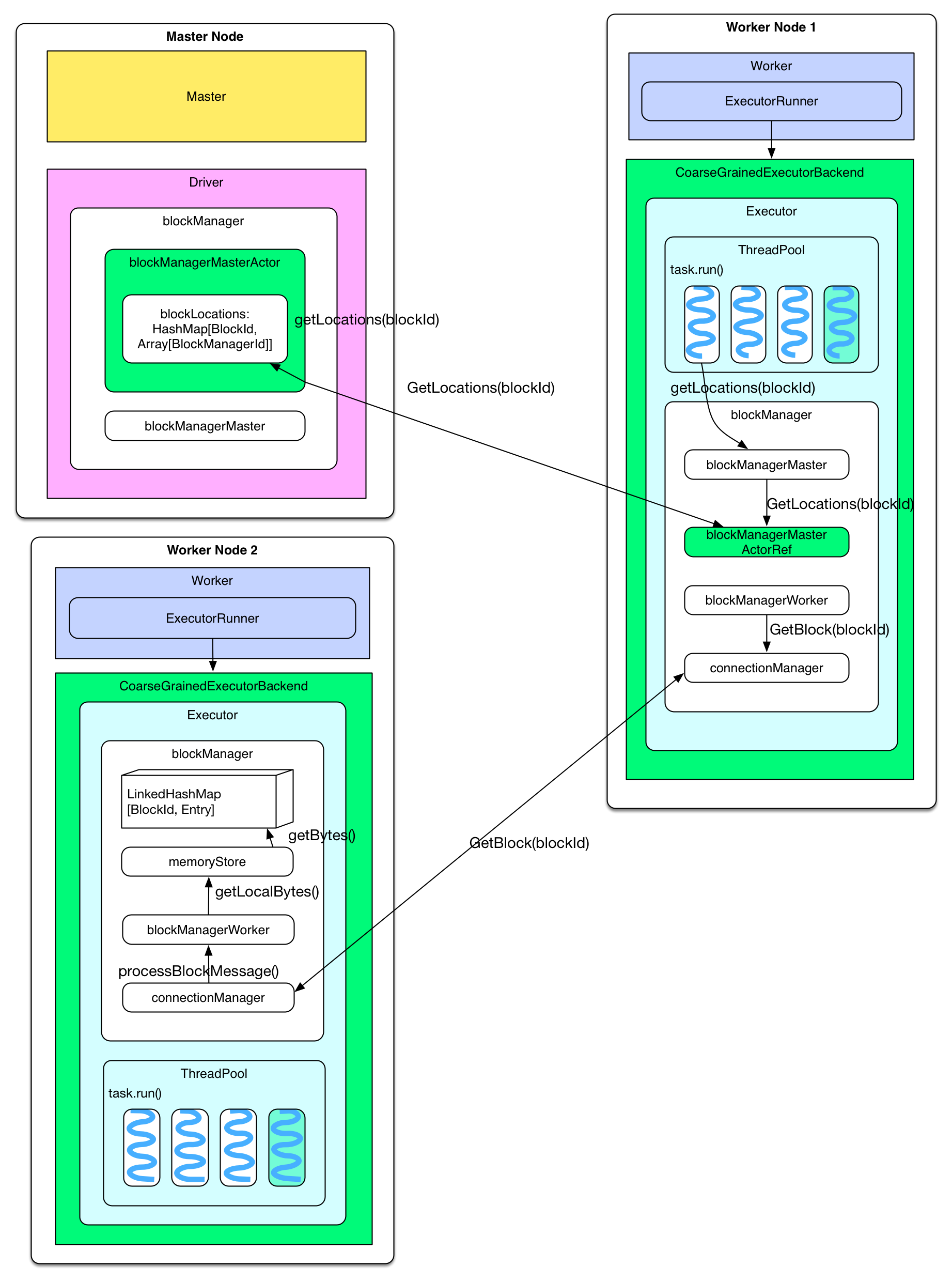
the storage location of cached partition: the blockManager of the node on which a partition is cached will notify the blockManagerMasterActor on master by saying that an RDD partition is cached. This information will be stored in the blockLocations: HashMap of blockMangerMasterActor. When a task needs a cached RDD, it will send blockManagerMaster.getLocations(blockId) request to driver to get the partition's location, and the driver will lookup blockLocations to send back location info.
Read cached partition from the other nodes: a task gets cached partition's location info, and then it sends getBlock(blockId) request to the target node via connectionManager. The target node retrieves and sends back the cached partition from the memoryStore of the local blockManager.
Checkpoint
Q: What kind of RDD needs checkpoint ?
- the computation takes a long time
- the computing chain is too long
- depends too many RDDs
Actually, saving the output of ShuffleMapTask on local disk is also checkpoint, but it is just for data output of partition.
Q: When to checkpoint ?
As mentioned above, every time a computed partition needs to be cached, it is cached into memory. However, checkpoint does not follow the same principle. Instead, it waits until the end of a job, and launches another job to finish checkpoint. An RDD which needs to be checkpointed will be computed twice; thus it is suggested to do a rdd.cache() before rdd.checkpoint(). In this case, the second job will not recompute the RDD. Instead, it will just read cache. In fact, Spark offers rdd.persist(StorageLevel.DISK_ONLY) method, like caching on disk. Thus, it caches RDD on disk during its first computation, but this kind of persist and checkpoint are different, we will discuss the difference later.
Q: How to implement checkpoint ?
Here is the procedure:
RDD will be: [ Initialized --> marked for checkpointing --> checkpointing in progress --> checkpointed ]. In the end, it will be checkpointed.
Initialized
On driver side, after rdd.checkpoint() is called, the RDD will be managed by RDDCheckpointData. User should set the storage path for check point (on hdfs).
marked for checkpointing
After initialization, RDDCheckpointData will mark RDD MarkedForCheckpoint.
checkpointing in progress
When a job is finished, finalRdd.doCheckpoint() will be called. finalRDD scans the computing chain backward. When meeting an RDD which needs to be checkpointed, the RDD will be marked CheckpointingInProgress, and then the configuration files (for writing to hdfs), like core-site.xml, will be broadcast to blockManager of the other work nodes. After that, a job will be launched to finish checkpoint:
rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf))
checkpointed
After the job finishes checkpoint, it will clean all the dependencies of the RDD and set the RDD to checkpointed. Then, add a supplementary dependency and set the parent RDD as CheckpointRDD. The checkpointRDD will be used in the future to read checkpoint files from file system and then generate RDD partitions
What's interesting is the following:
Two RDDs are checkpointed in driver program, but only the result (see code below) is successfully checkpointed. Not sure whether it is a bug or only that the downstream RDD will be intentionally checkpointed.
val data1 = Array[(Int, Char)]((1, 'a'), (2, 'b'), (3, 'c'),
(4, 'd'), (5, 'e'), (3, 'f'), (2, 'g'), (1, 'h'))
val pairs1 = sc.parallelize(data1, 3)
val data2 = Array[(Int, Char)]((1, 'A'), (2, 'B'), (3, 'C'), (4, 'D'))
val pairs2 = sc.parallelize(data2, 2)
pairs2.checkpoint
val result = pairs1.join(pairs2)
result.checkpoint
Q: How to read checkpointed RDD ?
runJob() will call finalRDD.partitions() to determine how many tasks there will be. rdd.partitions() checks if the RDD has been checkpointed via RDDCheckpointData which manages checkpointed RDD. If yes, return the partitions of the RDD (Array[Partition]). When rdd.iterator() is called to compute RDD's partition, computeOrReadCheckpoint(split: Partition) is also called to check if the RDD is checkpointed. If yes, the parent RDD's iterator(), a.k.a CheckpointRDD.iterator() will be called. CheckpointRDD reads files on file system to produce RDD partition. That's why a parent CheckpointRDD is added to checkpointed rdd trickly.
Q: the difference between cache and checkpoint ?
Here is the an answer from Tathagata Das:
There is a significant difference between cache and checkpoint. Cache materializes the RDD and keeps it in memory (and/or disk). But the lineage(computing chain)of RDD (that is, seq of operations that generated the RDD) will be remembered, so that if there are node failures and parts of the cached RDDs are lost, they can be regenerated. However, checkpoint saves the RDD to an HDFS file and actually forgets the lineage completely. This allows long lineages to be truncated and the data to be saved reliably in HDFS, which is naturally fault tolerant by replication.
Furthermore, rdd.persist(StorageLevel.DISK_ONLY) is also different from checkpoint. Through the former can persist RDD partitions to disk, the partitions are managed by blockManager. Once driver program finishes, which means the thread where CoarseGrainedExecutorBackend lies in stops, blockManager will stop, the RDD cached to disk will be dropped (local files used by blockManager will be deleted). But checkpoint will persist RDD to HDFS or local directory. If not removed manually, they will always be on disk, so they can be used by the next driver program.
Discussion
When Hadoop MapReduce executes a job, it keeps persisting data (writing to HDFS) at the end of every task and every job. When executing a task, it keeps swapping between memory and disk, back and forth. The problem of Hadoop is that task needs to be re-executed if any error occurs, e.g. shuffle stopped by errors will have only half of the data persisted on disk, and then the persisted data will be recomputed for the next run of shuffle. Spark's advantage is that, when error occurs, the next run will read data from checkpoint, but the downside is that checkpoint needs to execute the job twice.
Example
package internals
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object groupByKeyTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("GroupByKey").setMaster("local")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/Users/xulijie/Documents/data/checkpoint")
val data = Array[(Int, Char)]((1, 'a'), (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h')
)
val pairs = sc.parallelize(data, 3)
pairs.checkpoint
pairs.count
val result = pairs.groupByKey(2)
result.foreachWith(i => i)((x, i) => println("[PartitionIndex " + i + "] " + x))
println(result.toDebugString)
}
}